Energy-Efficient and High-Performance Deep Learning and Artificial Intelligence Systems
Block-Circulant Matrix-Based Deep Learning Systems 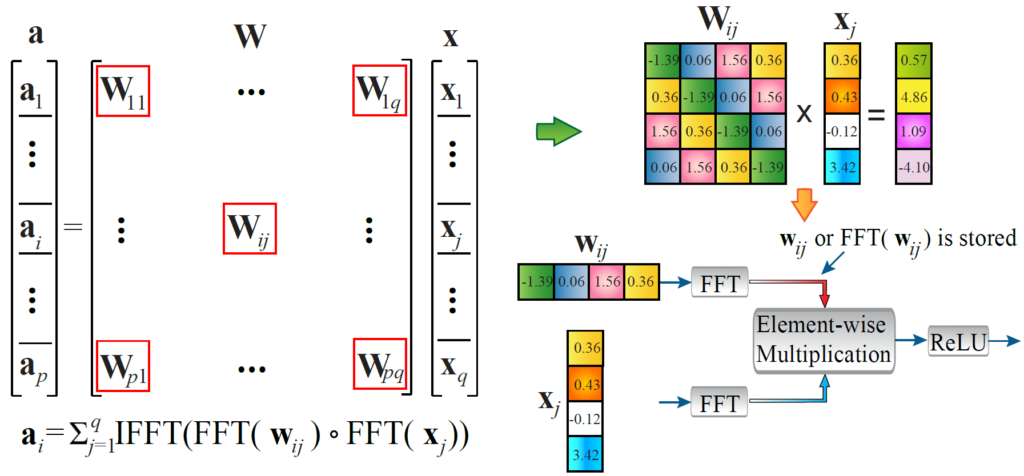
[AAAI’18][ICML’17][MICRO’17][ICCAD’17]
The rapidly expanding model size in deep learning systems is posing a significant restriction on both the computation and weight storage, for both inference and training, and on both high-performance computing systems and low-power embedded system and IoT applications. In order to overcome these limitations, we propose a holistic framework of incorporating structured matrices (block-circulant matrices) into deep learning systems, and could achieve (i) simultaneous reduction on weight storage and computational complexities, (ii) simultaneous speedup of training and inference, and (iii) generality and fundamentality that can be adopted to both software and hardware implementations, different platforms, and different neural network types, sizes, and scalability.
Besides algorithm-level achievements, our framework has (i) a solid theoretical foundation to prove that our approach will converge to the same “effectiveness” as deep learning without compression; (ii) platform-specific implementations and optimizations on smartphones, FPGAs, and ASIC circuits. We demonstrate that our smartphone-based implementation achieves the similar speed of GPU and existing ASIC implementations on the same application. Our FPGA-based implementations for deep learning systems and LSTM networks could achieve 10X+ energy efficiency improvement compared with state-of-the-arts, and even higher energy efficiency gain compared with IBM TrueNorth. Our proposed framework can achieve 3.5 TOPS performance in FPGAs, and is the first to enable nano-second level recognition speed for image recognition tasks.
SC-DCNN: Deep Convolutional Neural Networks using Stochastic Computing
[ASPLOS’17][IJCNN’17][DATE’17][PloS One submission] 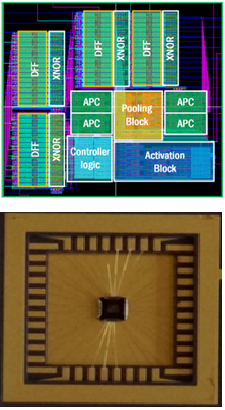
Stochastic Computing (SC), which uses a bit-stream to represent a number within [-1, 1] by counting the number of ones in the bit-stream, has high potential for implementing DCNNs with high scalability and ultra-low hardware footprint. Since multiplications and additions can be calculated using AND gates and multiplexers in SC, significant reductions in power (energy) and hardware footprint can be achieved.
In this project, we propose SC-DCNN, the first comprehensive design and optimization framework of SC-based DCNNs, using a bottom-up approach. We first design the function blocks that perform the basic operations in DCNN, including inner product, pooling, and activation function. Then we propose four designs of feature extraction blocks, which are in charge of extracting features from input feature maps, by connecting different basic function blocks with joint optimization. Putting all together, SC-DCNN is holistically optimized to minimize area and power (energy) consumption while maintaining high network accuracy.
The stochastic computing based deep learning systems are especially suitable for the emerging devices, due to the limited scalability in fabricating those devices. In 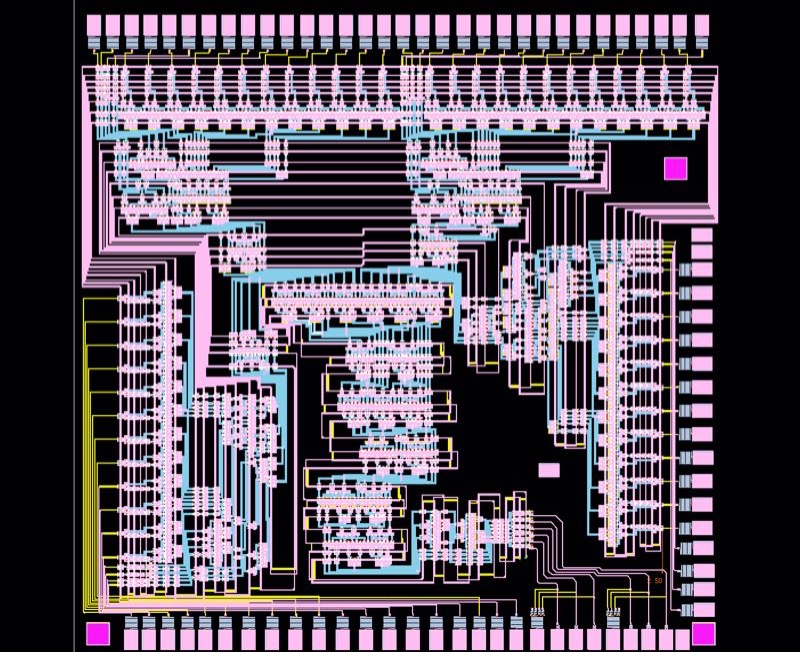 collaboration with Yokohama National University, Japan, we have developed the first generation of stochastic computing-based deep learning system using the Josephson Junction superconducting devices (using the AQFP logic, more specifically). It has the clear advantage of 10^4 to 10^5 energy efficiency gain compared with the state-of-the-art CMOS technology. The first and second prototypes are currently under tapeout and testing.
collaboration with Yokohama National University, Japan, we have developed the first generation of stochastic computing-based deep learning system using the Josephson Junction superconducting devices (using the AQFP logic, more specifically). It has the clear advantage of 10^4 to 10^5 energy efficiency gain compared with the state-of-the-art CMOS technology. The first and second prototypes are currently under tapeout and testing.
Deep Reinforcement Learning in CPS and Autonomous Systems and Precision Medicine
[INFOCOM’18][ICDCS’17][ICHI’17][Nature Scientific Report submission][DAC’17][ICCAD’17]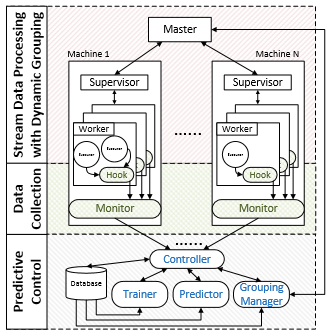
Deep Reinforcement Learning (DRL), initially developed by DeepMind, is a data-driven, model-free framework that determines the appropriate action at a potentially high-dimensional state. It has achieved significant success in game playing with sophisticated state spaces (e.g., AlphaGo). Our group becomes one of the first to adopt the DRL technique to solve complicated control problems in cyber-physical and autonomous systems, which exhibit high-dimensional state space, potentially high-dimensional action space, and time-variant environments. More specifically, we develop a general, actor-critic DRL framework, comprising an offline DNN training phase and an online inference/updating phase, for these data-driven complex control problemswith high-dimensional action spaces.
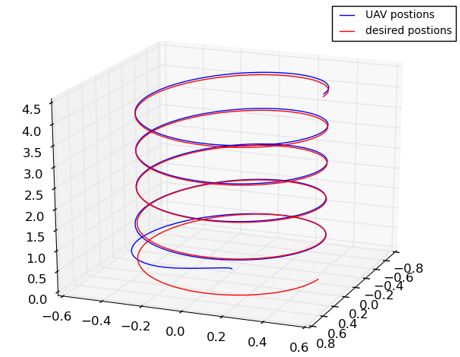
We have investigated very broad applications of the general DRL framework, on big data systems, unmanned aerial vehicles (UAVs), and precision medicine, to name a few. We derived the application on an Apache Storm-based Distributed Stream Data Processing Systems (DSDPS), which process unbounded large streams of continuous data in a distributed and real-time manner. By adopting the DRL framework, we are able to (i) reduce the average end-to-end tuple processing time by up to 39.6% compared with the Storm’s default scheduler, and (ii) incorporate the fault detection and bypassing capability. As a second example, we apply the DRL framework to automatically derive the optimal control sequence (position, motor force and torque, etc.) for a UAV in order to follow a pre-defined route or achieve certain target. Our proposed method significantly outperforms the PID controller integrated in state-of-the-art UAVs and can potentially lead to the future fully autonomous UAVs without the need of remote controls. Last but not least, we are the first to apply DRL for precision medicines. More specifically, we develop a DRL-based dynamic treatment framework for the patients diagnosed with Acute Myeloid Leukemia who undergo the hematopoietic cell transplantation (HCT). We demonstrated promising results in both predicting human experts’ decisions and making treatment suggestions.